
Portfolio Debug
Total items: 4
title: From CNNs to Transformers: Top-k Image Retrieval path: _portfolio/3_Top-k-Image-Retrieval.md output: <!doctype html><html lang="en" class="no-js"><head>
From CNNs to Transformers: Top-k Image Retrieval Home </head><body> <div class="masthead"><div class="masthead__inner-wrap"><div class="masthead__menu"><nav id="site-nav" class="greedy-nav"> <ul class="visible-links"> <li class="masthead__menu-item masthead__menu-item--lg persist"> Home</li><li class="masthead__menu-item"> About</li><li class="masthead__menu-item"> Portfolio</li><li class="masthead__menu-item"> Gallery</li><li class="masthead__menu-item"> CV</li><li class="masthead__menu-item"> Blog</li><li class="masthead__menu-item"> Contact</li><li id="theme-toggle" class="masthead__menu-item persist tail"> </li></ul><ul class="hidden-links hidden"></ul></nav></div></div></div><div class="initial-content"><div id="main" role="main"><article class="page" itemscope itemtype="http://schema.org/CreativeWork"><div class="page__inner-wrap"><header><h1 class="page__title" itemprop="headline">From CNNs to Transformers: Top-k Image Retrieval</h1><p class="page__date"> Published: </p></header><section class="page__content" itemprop="text"><p>View code on GitHub
Read full paper (CVPR format)</p><p>This was a competition project for our Machine Learning course—four members team which the goal to: retrieve the top-10 most similar images for each query. Queries were real photos of celebrities, and the gallery was synthetic AI-generated portraits of the same people, but rendered in completely different artistic styles.</p><p>This wasn’t a pixel-matching problem. A real photo of someone in a suit and a cartoon-style portrait of the same person share almost nothing at the texture level. We needed semantic understanding—models that could reason about identity despite radical visual differences.</p><hr /><h2 id="my-role--focus">My Role & Focus</h2><p>I worked in a team of four, and I focused mainly on two areas:</p><p>CLIP — I ran the CLIP variants (ViT-B/32, B/16, L/14), handling both frozen and fine-tuned setups. This involved figuring out how to properly unfreeze transformer layers, tuning learning rates, and eventually discovering we’d been doing fine-tuning wrong the entire competition.</p><p>Metrics design — We initially used generic retrieval metrics, but I realized we needed something aligned with the competition’s weighted scoring system (600 points for Top-1, 300 for Top-5, 100 for Top-10). I built the evaluation pipeline that tracked this properly and helped us understand where models were actually failing.</p><p>Looking back, one thing I’d change: CLIP has its own contrastive loss built-in, and we should have used it from the start instead of reinventing it post-competition.</p><hr /><h2 id="what-we-tried">What We Tried</h2><p>We tested everything: ResNets, EfficientNets, GoogLeNet, DINOv2, and multiple CLIP variants. We experimented with pooling strategies (Global Average Pooling vs. Generalized Mean Pooling), froze vs. fine-tuned encoders, and ran ablations on loss functions.</p><p>The pattern that emerged was clear: transformers consistently outperformed CNNs when semantic similarity mattered more than texture matching. CLIP, pretrained on 400M image-text pairs, had learned to embed meaning rather than just pixels. It could look at a real photo and a stylized illustration and understand they depicted the same person—something ResNets struggled with.</p><p>But here’s where it got interesting: having a powerful architecture didn’t automatically translate to good results.</p><hr /><h2 id="the-fine-tuning-fix">The Fine-Tuning Fix</h2><p>During the competition, we were convinced we were fine-tuning CLIP properly. We weren’t.</p><p>The training loop had a subtle bug: parameter updates weren’t propagating to the transformer blocks. We were essentially running frozen inference with an unfrozen classification head, which is why our competition-day score with ViT-L/14 was 510.24—decent, but nowhere near its potential.</p><p>Post-competition, We went back and debugged the entire training pipeline:</p><ul><li>Fixed layer unfreezing to ensure gradients flowed through all transformer blocks</li><li>Added gradient accumulation (simulating larger batches without OOM errors)</li><li>Implemented explicit memory management (torch.cuda.empty_cache())</li><li>Replaced pure cross-entropy with a hybrid loss: cross-entropy + contrastive learning</li></ul><p>That last point was critical. Cross-entropy alone pushes classes apart but doesn’t preserve relational structure in the embedding space. If two celebrities look similar, their embeddings should reflect that, even if they’re different identities. Contrastive loss enforces this: pull same-class embeddings together, push different-class embeddings apart.</p><p>With these fixes, ViT-L/14’s score jumped to 791.82—a +281.6 improvement. That’s not a minor bump; that’s the difference between a working training pipeline and a broken one.</p><hr /><h2 id="why-clip-actually-worked">Why CLIP Actually Worked</h2><p>CLIP’s advantage comes from its pretraining objective. It’s trained on image-caption pairs, learning to align visual and textual semantics in a shared embedding space. This gives it abstract reasoning capabilities that CNNs don’t have.</p><p>A CNN sees edges, textures, and color gradients. CLIP sees “a person with specific facial features” regardless of whether they’re photographed or illustrated. When you’re matching across massive domain shifts, that’s the capability you need.</p><p>But—and this is important—CLIP’s zero-shot performance wasn’t enough. Even with 400M pretraining examples, it needed task-specific fine-tuning to distinguish between real and synthetic faces in our dataset. The trick was doing that fine-tuning correctly, which we initially didn’t.</p><hr /><h2 id="lessons-id-apply-next-time">Lessons I’d Apply Next Time</h2><p>Use native model tools when they exist. CLIP has a built-in contrastive loss designed for its architecture. We ended up implementing our own variant post-competition, which worked, but it would’ve been smarter to start with what the authors provided.</p><p>Infrastructure matters as much as architecture. The difference between our competition score and our post-competition score wasn’t about discovering a better model—it was about fixing memory bottlenecks and gradient flow. Scaling laws are real: larger models perform better, but only if your training pipeline can actually train them.</p><p>Metrics guide everything. We spent the first half of the competition optimizing for the wrong thing because our evaluation didn’t match the competition’s weighted scoring. Once I built the proper metric tracker, decision-making became much clearer.</p><p>Ablations reveal more than leaderboards. We ran side-by-side comparisons of every architecture, pooling strategy, and loss function. That’s how we learned transformers systematically beat CNNs for semantic retrieval. The leaderboard told us scores; ablations told us why.</p><hr /><h2 id="results">Results</h2><table><thead><tr><th>Model</th><th>Configuration</th><th>Top-k Accuracy</th></tr></thead><tbody><tr><td>CLIP ViT-L/14</td><td>Fine-tuned, hybrid loss (post-competition)</td><td>791.82</td></tr><tr><td>CLIP ViT-L/14</td><td>Fine-tuned, CE only (competition day)</td><td>510.24</td></tr><tr><td>CLIP ViT-B/16</td><td>Fine-tuned</td><td>603.85</td></tr><tr><td>EfficientNet-B3</td><td>Fine-tuned, GAP</td><td>0.8513 (Precision@K on Animals dataset)</td></tr><tr><td>ResNet-152</td><td>Fine-tuned</td><td>~0.72 (Precision@K)</td></tr></tbody></table><p>The final system retrieves semantically correct matches even when query and gallery images look nothing alike visually—exactly what we needed.</p><hr /><h2 id="technical-stack">Technical Stack</h2><p>Models: CLIP (ViT-B/32, B/16, L/14), DINOv2, EfficientNet (B0, B3), ResNet (34, 50, 101, 152), GoogLeNet
Framework: PyTorch, torchvision, Hugging Face Transformers
Evaluation: Custom weighted Top-k accuracy aligned with competition scoring
Training optimizations: Gradient accumulation, mixed precision (fp16), explicit memory management
Collaboration: Team of 4, version control via GitHub, experiments logged in JSON</p><hr /><p>making models trainable, not just picking the right architecture.</p><p>We had access to ViT-L/14 from day one. It took us time to actually unlock its performance because the barrier wasn’t the model—it was memory constraints, gradient bugs, and loss function design.</p><hr /><p>📂 Full code and experiments
📄 Technical paper (CVPR format)</p><p>Team: Silvia Bortoluzzi, Diego Conti, Sara Lammouchi, Tereza Sásková
Course: Introduction to Machine Learning, University of Trento (2024–2025)</p><hr /></section><footer class="page__meta"></footer><nav class="pagination"> Previous Next </nav></div></article></div></div><div class="page__footer"><footer> <footer class="page__footer"><div class="page__footer-follow"><ul class="social-icons"><li> GitHub</li></ul></div></footer></footer></div></body></html>url: /portfolio/topk-image-retrieval/ link: teaser: /Users/terezasaskova/Desktop/portfolio-1/images/home-bg.jpg
title: Reddit & Conflict: Israel–Palestine Discourse Analysis path: _portfolio/conflict-analysis.md output: <!doctype html><html lang="en" class="no-js"><head>
Reddit & Conflict: Israel–Palestine Discourse Analysis Home </head><body> <div class="masthead"><div class="masthead__inner-wrap"><div class="masthead__menu"><nav id="site-nav" class="greedy-nav"> <ul class="visible-links"> <li class="masthead__menu-item masthead__menu-item--lg persist"> Home</li><li class="masthead__menu-item"> About</li><li class="masthead__menu-item"> Portfolio</li><li class="masthead__menu-item"> Gallery</li><li class="masthead__menu-item"> CV</li><li class="masthead__menu-item"> Blog</li><li class="masthead__menu-item"> Contact</li><li id="theme-toggle" class="masthead__menu-item persist tail"> </li></ul><ul class="hidden-links hidden"></ul></nav></div></div></div><div class="initial-content"><div id="main" role="main"><article class="page" itemscope itemtype="http://schema.org/CreativeWork"><div class="page__inner-wrap"><header><h1 class="page__title" itemprop="headline">Reddit & Conflict: Israel–Palestine Discourse Analysis</h1><p class="page__date"> Published: </p></header><section class="page__content" itemprop="text"><p>View code on GitHub
View visualizations</p><p>This project focus on the relationship between real-world conflict events and online conntent on social media using cross-correlation analysis and unsupervised topic modeling. The central research question: Do social media discussions respond to geopolitical violence in real-time?</p><p>We integrated two data sources—Reddit comment streams (unstructured social data) and ACLED conflict events (structured geopolitical data)—to quantify how online attention patterns correlate with offline violence in Gaza and the West Bank. The analysis revealed a 15-day lag in peak discourse volume relative to conflict intensity, with evidence of selective amplification based on event severity.</p><hr /><h2 id="problem-formulation--data-integration-challenges">Problem Formulation & Data Integration Challenges</h2><h3 id="data-sources">Data Sources</h3><p>Reddit corpus: 2.1GB dataset spanning March–June 2025, containing approximately 1.2M comments from conflict-related subreddits. Raw text exhibits high variability: colloquial language, sarcasm, emotionally charged rhetoric, and domain-specific terminology.</p><p>ACLED event database: Structured records of 5,000+ conflict incidents with temporal, geographic, and categorical metadata (event type, fatalities, civilian targeting). Events include battles, explosions, targeted killings, and violence against civilians.</p><h3 id="core-challenge-cross-domain-alignment">Core Challenge: Cross-Domain Alignment</h3><p>The primary challenge was aligning asynchronous, semantically distinct data streams for temporal comparison:</p><ol><li><p>Semantic extraction from noisy text: Reddit comments required aggressive preprocessing to extract meaningful signal. Standard NLP pipelines underperformed due to domain-specific jargon, neologisms, and syntactic irregularities.</p></li><li><p>Event granularity mismatch: ACLED provides incident-level records with fine-grained categorization (20+ event subtypes). Reddit discourse operates at thematic levels that don’t map cleanly to ACLED’s taxonomy. We needed dimensionality reduction on both sides.</p></li><li><p>Temporal aggregation: Reddit exhibits strong day-of-week effects and time-of-day biases. ACLED events cluster around military operations schedules. Naive daily aggregation produced non-stationary time series unsuitable for correlation analysis.</p></li></ol><hr /><h2 id="methodology">Methodology</h2><h3 id="text-preprocessing-pipeline">Text Preprocessing Pipeline</h3><p>We implemented a multi-stage cleaning and normalization pipeline:</p><p>Regex-based cleaning:</p><ul><li>URL removal via pattern matching</li><li>Punctuation stripping</li><li>Numeric token removal</li></ul><p>spaCy-based linguistic normalization:</p><ul><li>Lemmatization to preserve semantic fidelity (e.g., “bombing” to “bomb”)</li><li>Stopword removal with length filtering (tokens > 2 characters)</li><li>Part-of-speech tagging for linguistic features</li></ul><p>Key decisions:</p><ul><li>Lemmatization over stemming: Preserved semantic fidelity rather than aggressive truncation.</li><li>Sentence boundary detection: Retained via spaCy’s sentencizer to preserve local context for topic modeling.</li><li>Vectorization constraints: CountVectorizer with max_df=0.9, min_df=10 to filter ultra-frequent generic terms and ultra-rare noise tokens.</li></ul><p>Computational optimization: Processed in 1000-row chunks with batch spaCy inference (batch_size=32) to avoid memory overflow on 2.1GB corpus.</p><h3 id="acled-event-categorization">ACLED Event Categorization</h3><p>ACLED’s fine-grained event taxonomy was collapsed into two high-level categories aligned with discourse relevance:</p><ul><li>Combat: Battles + Explosions/Remote violence (military-to-military engagements)</li><li>Civilian Harm: Violence against civilians (asymmetric targeting, likely to generate moral outrage)</li></ul><p>This reduction was theoretically motivated: prior research in media studies suggests public attention gravitates toward civilian casualties over military operations (Galtung & Ruge’s news value theory).</p><h3 id="temporal-alignment--smoothing">Temporal Alignment & Smoothing</h3><p>Both datasets were aggregated to daily granularity and smoothed using a 7-day centered rolling window.</p><p>Rationale:</p><ul><li>Removes high-frequency noise (weekend effects, single-day spikes)</li><li>Preserves medium-term trends (weekly discourse cycles)</li><li>Centers the window to avoid phase shifts in correlation analysis</li></ul><h3 id="cross-correlation-analysis">Cross-Correlation Analysis</h3><p>To detect temporal lag, we computed the cross-correlation function between ACLED event counts and Reddit post volumes. Both series were z-score normalized prior to correlation to ensure scale invariance.</p><p>Implementation approach:</p><ul><li>Standardized both time series (mean=0, standard deviation=1)</li><li>Computed correlation at all possible time offsets</li><li>Identified lag corresponding to maximum correlation</li></ul><p>Result: Maximum correlation of r=0.56 at lag +15 days, indicating Reddit discourse systematically trails conflict events by approximately two weeks.</p><hr /><h2 id="topic-modeling-latent-dirichlet-allocation">Topic Modeling: Latent Dirichlet Allocation</h2><p>To characterize thematic structure, we applied LDA to the Reddit corpus using a bag-of-words representation.</p><p>Model configuration:</p><ul><li>n_components=5 (determined via coherence score evaluation)</li><li>max_iter=5 (sufficient for convergence on this corpus size)</li><li>Document-term matrix generated via CountVectorizer with preprocessed text</li></ul><p>Extracted topics (top-10 terms per topic):</p><table><thead><tr><th>Topic</th><th>Dominant Terms</th><th>Interpretation</th></tr></thead><tbody><tr><td>0</td><td>airstrike, IDF, Gaza, bomb, military</td><td>Military Operations</td></tr><tr><td>1</td><td>hospital, aid, civilians, killed, UNRWA</td><td>Humanitarian Crisis</td></tr><tr><td>2</td><td>Netanyahu, Iran, Trump, Biden, blame</td><td>Geopolitical Attribution</td></tr><tr><td>3</td><td>protest, march, campus, solidarity</td><td>Activism & Mobilization</td></tr><tr><td>4</td><td>media, bias, coverage, propaganda</td><td>Meta-Discourse on Framing</td></tr></tbody></table><p>Temporal topic dynamics: We computed daily topic distributions by aggregating per-document topic assignments, then overlaid these on the ACLED fatality timeline to identify event-discourse associations.</p><h3 id="key-finding-selective-amplification">Key Finding: Selective Amplification</h3><p>Topic intensity correlated with event severity (measured by fatalities), not event frequency:</p><ul><li>High-fatality events (>50 deaths) generated 10x more discussion than low-level violence</li><li>June 17 airstrike on aid convoy (85 fatalities) produced massive spike in Topic 1 (Humanitarian Crisis)</li><li>Sustained low-intensity clashes (<10 fatalities/day) generated minimal Reddit activity</li></ul><p>This suggests discourse operates via a threshold activation function: events must exceed a salience threshold to penetrate public attention.</p><hr /><h2 id="technical-implementation--engineering-decisions">Technical Implementation & Engineering Decisions</h2><h3 id="why-lda-over-transformer-based-models">Why LDA Over Transformer-Based Models?</h3><p>We evaluated both LDA and BERTopic:</p><table><thead><tr><th>Method</th><th>Pros</th><th>Cons</th><th>Decision Rationale</th></tr></thead><tbody><tr><td>LDA</td><td>Fast, interpretable, provides topic distributions</td><td>Bag-of-words assumption, no semantic embeddings</td><td>Chosen for exploratory analysis; sufficient for thematic clustering</td></tr><tr><td>BERTopic</td><td>Semantic embeddings, better coherence</td><td>Computationally expensive, less transparent</td><td>Viable for future work with GPU resources</td></tr></tbody></table><p>LDA was sufficient because we needed coarse thematic categories, not fine-grained semantic distinctions. BERTopic would add value if distinguishing between subtopics (e.g., “hospital bombing” vs. “hospital blockade”).</p><h3 id="memory--computational-optimization">Memory & Computational Optimization</h3><p>Challenge: 2.1GB corpus exceeded single-pass memory limits.</p><p>Solution: Streaming pipeline with chunked processing using pandas chunksize parameter. Each chunk was processed independently and appended to output file incrementally.</p><p>Alternative considered: Dask for distributed processing. Not adopted due to overhead for single-machine workload and lack of GPU parallelization needs.</p><h3 id="cross-correlation-vs-granger-causality">Cross-Correlation vs. Granger Causality</h3><p>Granger causality would provide directional inference (does X cause Y?), but requires:</p><ul><li>Stationarity (violated by trend components in both series)</li><li>Linear VAR assumptions (unlikely given nonlinear discourse dynamics)</li></ul><p>Cross-correlation is more robust for:</p><ul><li>Exploratory lag detection</li><li>Non-stationary data</li><li>Pattern similarity over causal inference</li></ul><p>Future work could apply Transfer Entropy for model-free causal detection.</p><hr /><h2 id="results--quantitative-findings">Results & Quantitative Findings</h2><table><thead><tr><th>Metric</th><th>Value</th><th>Interpretation</th></tr></thead><tbody><tr><td>Peak Cross-Correlation</td><td>r=0.56 at lag +15 days</td><td>Reddit lags conflict events by approximately 2 weeks</td></tr><tr><td>Topic 1 (Humanitarian)</td><td>28% of total discourse</td><td>Dominant theme during high-fatality events</td></tr><tr><td>Selective Attention Ratio</td><td>10:1 (high vs. low fatality)</td><td>Public attention is event-severity dependent</td></tr><tr><td>Corpus Size</td><td>1.2M comments, 2.1GB</td><td>Processed in <2 hours with chunk-based pipeline</td></tr></tbody></table><h3 id="validation-annotated-event-mapping">Validation: Annotated Event Mapping</h3><p>We manually validated the top 5 deadliest events against discourse spikes:</p><table><thead><tr><th>Date</th><th>Event Description</th><th>Fatalities</th><th>Reddit Spike (7-day avg)</th></tr></thead><tbody><tr><td>June 17</td><td>Airstrike on aid convoy</td><td>85</td><td>+320% vs. baseline</td></tr><tr><td>May 18</td><td>Sustained urban combat</td><td>62</td><td>+180% vs. baseline</td></tr><tr><td>March 18</td><td>Hospital complex strike</td><td>51</td><td>+250% vs. baseline</td></tr></tbody></table><p>All high-fatality events produced discourse spikes within the 15±5 day window, confirming lag consistency.</p><hr /><h2 id="limitations--future-directions">Limitations & Future Directions</h2><p>Sentiment analysis integration: Current analysis focuses on volume and topics. Incorporating polarity and emotion detection (e.g., via VADER or transformer-based sentiment models) would capture tonal shifts beyond thematic changes.</p><p>Event causality modeling: Cross-correlation establishes temporal association, not causation. Transfer entropy or dynamic Bayesian networks could provide causal inference.</p><p>Longitudinal extension: Analysis covers 4 months. Extending to multi-year datasets would test lag stability across different conflict phases (escalation vs. de-escalation).</p><p>Multilingual expansion: Current corpus is English-only. Incorporating Arabic and Hebrew discourse from regional platforms would provide comparative analysis of information asymmetries.</p><p>Automated event categorization: Manual ACLED categorization could be replaced with supervised classification using event embeddings (e.g., BERT fine-tuned on ACLED descriptions).</p><hr /><h2 id="technical-stack">Technical Stack</h2><p>Core Libraries: pandas, NumPy, spaCy, scikit-learn , gensim , scipy NLP Pipeline: Regex normalization → spaCy lemmatization → CountVectorizer → LDA
Statistical Methods: Cross-correlation, rolling window smoothing, z-score normalization
Visualization: Matplotlib with dual-axis time-series plots and lag correlation graphs
Data Sources: Reddit, ACLED
Compute Environment: Single-node processing, 16GB RAM, chunked I/O for memory efficiency</p><hr /><h2 id="implications-for-computational-social-science">Implications for Computational Social Science</h2><p>This work demonstrates that social media discourse operates on delayed, selective attention mechanisms when responding to geopolitical events. The 15-day lag suggests information diffusion through news cycles, secondary commentary, and thematic framing processes rather than direct real-time observation.</p><p>The selective amplification finding aligns with news value theory: events must be exceptional (high fatality, civilian targeting) to penetrate the attention economy. Low-intensity violence—despite cumulative humanitarian impact—fails to generate sustained discourse.</p><p>From a methodological standpoint, the project highlights the importance of temporal alignment techniques in cross-domain analysis. Naive correlation without smoothing and lag detection would have produced spurious null results.</p><hr /><p>📂 Full implementation and reproducible notebooks
📊 Visualization suite and data artifacts</p><p>Author: Tereza Sásková
Institution: University of Trento, Computational Social Science (Spring 2025)</p></section><footer class="page__meta"></footer><nav class="pagination"> Previous Next </nav></div></article></div></div><div class="page__footer"><footer> <footer class="page__footer"><div class="page__footer-follow"><ul class="social-icons"><li> GitHub</li></ul></div></footer></footer></div></body></html>url: /portfolio/reddit-conflict/ link: teaser: /images/portfolio/reddit-conflict/reddit_top5_LDA.png
title: Podcast Recommendation Platform path: _portfolio/2_podcast-recommendation-platform.md output: <!doctype html><html lang="en" class="no-js"><head>
Podcast Recommendation Platform Home </head><body> <div class="masthead"><div class="masthead__inner-wrap"><div class="masthead__menu"><nav id="site-nav" class="greedy-nav"> <ul class="visible-links"> <li class="masthead__menu-item masthead__menu-item--lg persist"> Home</li><li class="masthead__menu-item"> About</li><li class="masthead__menu-item"> Portfolio</li><li class="masthead__menu-item"> Gallery</li><li class="masthead__menu-item"> CV</li><li class="masthead__menu-item"> Blog</li><li class="masthead__menu-item"> Contact</li><li id="theme-toggle" class="masthead__menu-item persist tail"> </li></ul><ul class="hidden-links hidden"></ul></nav></div></div></div><div class="initial-content"><div id="main" role="main"><article class="page" itemscope itemtype="http://schema.org/CreativeWork"><div class="page__inner-wrap"><header><h1 class="page__title" itemprop="headline">Podcast Recommendation Platform</h1><p class="page__date"> Published: </p></header><section class="page__content" itemprop="text"><p>View code on GitHub</p><hr /><h2 id="-recommendation-system-for-podcasts">🎧 Recommendation System for Podcasts</h2><p>How do you recommend podcast episodes based both on personal preferences and topic similarities?</p><p>This project is an end-to-end data pipeline with a simple dashboard output. The goal was to combine user behavior patterns with semantic episode similarity, then serve recommendations through a reliable and modular architecture.</p><p>This work was completed as part of the Big Data Technologies course at the University of Trento, as a team effort. My main focus was on data ingestion, Kafka and Spark pipelines, and text processing + training components.</p><hr /><h2 id="️-system-architecture">🏗️ System Architecture</h2><p>A three-layer architecture that handles everything from raw audio ingestion to real-time serving:</p><p>Ingestion
Pull trending episodes from PodcastIndex (the open alternative to Spotify’s API), stream them through Kafka, and use Vosk for speech-to-text transcription.
User events (plays, likes, skips, completions) are simulated following realistic behavior patterns, all flowing through Kafka into Delta Lake.
We opted for simulation due to lack of real user data.</p><p>Processing
Two parallel pipelines:</p><ul><li>Content-based: Transcripts embedded using SentenceTransformers, with KNN similarities across the catalog. (In production, this would be replaced with ANN for scalability.)</li><li>Collaborative: User events aggregated into daily engagement scores, feeding a Spark ALS model for collaborative filtering.</li></ul><p>Serving
Final recommendations combine both scores:</p><blockquote><p>0.7 × ALS_score + 0.3 × content_similarity</p></blockquote><p>Results are stored in MongoDB for sub-100 ms lookups, and visualized in a Streamlit dashboard.</p><p> </p><hr /><h2 id="️-interesting-problems">⚙️ Interesting Problems</h2><h3 id="1-making-als-work-with-implicit-feedback">1. Making ALS Work with Implicit Feedback</h3><p>Collaborative filtering is simple when you have explicit ratings—but podcast listening is messy. Someone might play an episode for 10 seconds, or listen 90% and never “like” it.</p><p>We treated this as an implicit feedback problem where the rating is binary (interacted = yes/no) but the confidence varies.
</p><hr /><h2 id="️-interesting-problems">⚙️ Interesting Problems</h2><h3 id="1-making-als-work-with-implicit-feedback">1. Making ALS Work with Implicit Feedback</h3><p>Collaborative filtering is simple when you have explicit ratings—but podcast listening is messy. Someone might play an episode for 10 seconds, or listen 90% and never “like” it.</p><p>We treated this as an implicit feedback problem where the rating is binary (interacted = yes/no) but the confidence varies.
A full listen + like gets high confidence; a skip after 5% gets almost none.
After tuning, I found alpha = 40 and regParam = 0.08 produced balanced recommendations across the catalog.</p><hr /><h3 id="2-the-cold-start-problem-practically">2. The Cold-Start Problem, Practically</h3><p>New episodes start with zero engagement data.
Instead of maintaining two paths (content vs. collaborative), I compute embeddings immediately on ingestion and store them in MongoDB.
The hybrid scoring handles this naturally: new episodes rely fully on content similarity until ALS data accumulates.</p><hr /><h3 id="3-multi-language-variants-without-duplication">3. Multi-Language Variants Without Duplication</h3><p>PodcastIndex lists the same show in multiple languages. Without filtering, users saw multiple translations of the same episode.</p><p>The fix: define acanonical_episode_idgrouping all variants, and at serving time filter by user locale.
No NLP magic — just smart metadata use.</p><hr /><h3 id="4-built-in-ab-testing">4. Built-in A/B Testing</h3><p>We designed serving for early A/B tests.
A deterministic hash —hash(user_id + experiment_id) % 100— splits users into:</p><ul><li>0–49: hybrid recommendations</li><li>50–99: ALS-only</li></ul><p>This keeps user variants sticky across sessions, ensuring consistent engagement metrics.</p><hr /><h2 id="tech-choices">Tech Choices</h2><ul><li>Kafka – for replayable event transport and reproducibility.</li><li>Delta Lake – for schema evolution and time-travel.</li><li>Spark – unified framework for streaming + batch + ML.</li><li>Vosk – local STT, showing end-to-end capability without external APIs.</li><li>DuckDB – lightweight analytics directly from Delta with sub-second queries.</li></ul><hr /><h2 id="what-wed-do-differently">What We’d Do Differently</h2><p>If productionized:</p><ul><li>Replace simulated events with real user tracking (Segment/Snowplow).</li><li>Add model monitoring (drift, overfitting alerts via Evidently or Great Expectations).</li><li>Refactor the monolithic Airflow DAG into smaller modular DAGs for selective runs.</li></ul><hr /><h2 id="-results">📊 Results</h2><p> </p><hr /><p>📂 View the repository on GitHub
</p><hr /><p>📂 View the repository on GitHub
📘 Read architecture documentation</p></section><footer class="page__meta"></footer><nav class="pagination"> Previous Next </nav></div></article></div></div><div class="page__footer"><footer> <footer class="page__footer"><div class="page__footer-follow"><ul class="social-icons"><li> GitHub</li></ul></div></footer></footer></div></body></html>url: /portfolio/podcast-platform/ link: teaser: /images/dashboard.png
title: Weekly Registration System for Ski School Ski Zadov path: _portfolio/1_form_app.md output: <!doctype html><html lang="en" class="no-js"><head>
Weekly Registration System for Ski School Ski Zadov Home </head><body> <div class="masthead"><div class="masthead__inner-wrap"><div class="masthead__menu"><nav id="site-nav" class="greedy-nav"> <ul class="visible-links"> <li class="masthead__menu-item masthead__menu-item--lg persist"> Home</li><li class="masthead__menu-item"> About</li><li class="masthead__menu-item"> Portfolio</li><li class="masthead__menu-item"> Gallery</li><li class="masthead__menu-item"> CV</li><li class="masthead__menu-item"> Blog</li><li class="masthead__menu-item"> Contact</li><li id="theme-toggle" class="masthead__menu-item persist tail"> </li></ul><ul class="hidden-links hidden"></ul></nav></div></div></div><div class="initial-content"><div id="main" role="main"><article class="page" itemscope itemtype="http://schema.org/CreativeWork"><div class="page__inner-wrap"><header><h1 class="page__title" itemprop="headline">Weekly Registration System for Ski School Ski Zadov</h1><p class="page__date"> Published: </p></header><section class="page__content" itemprop="text"><h2 id="weekly-registration-system-for-ski-school">Weekly Registration System for Ski School</h2><p>This project is a production-ready webpage application developed for Ski Zadov, my family ski school, in order to automate and manage weekly registrations for their seasonal ski courses.</p><blockquote><p>🏔️ Live project:
👉 https://vikendovelyzovani.zadov.cz/
(The live version is active, though the backend database is still being developed.)</p></blockquote><p>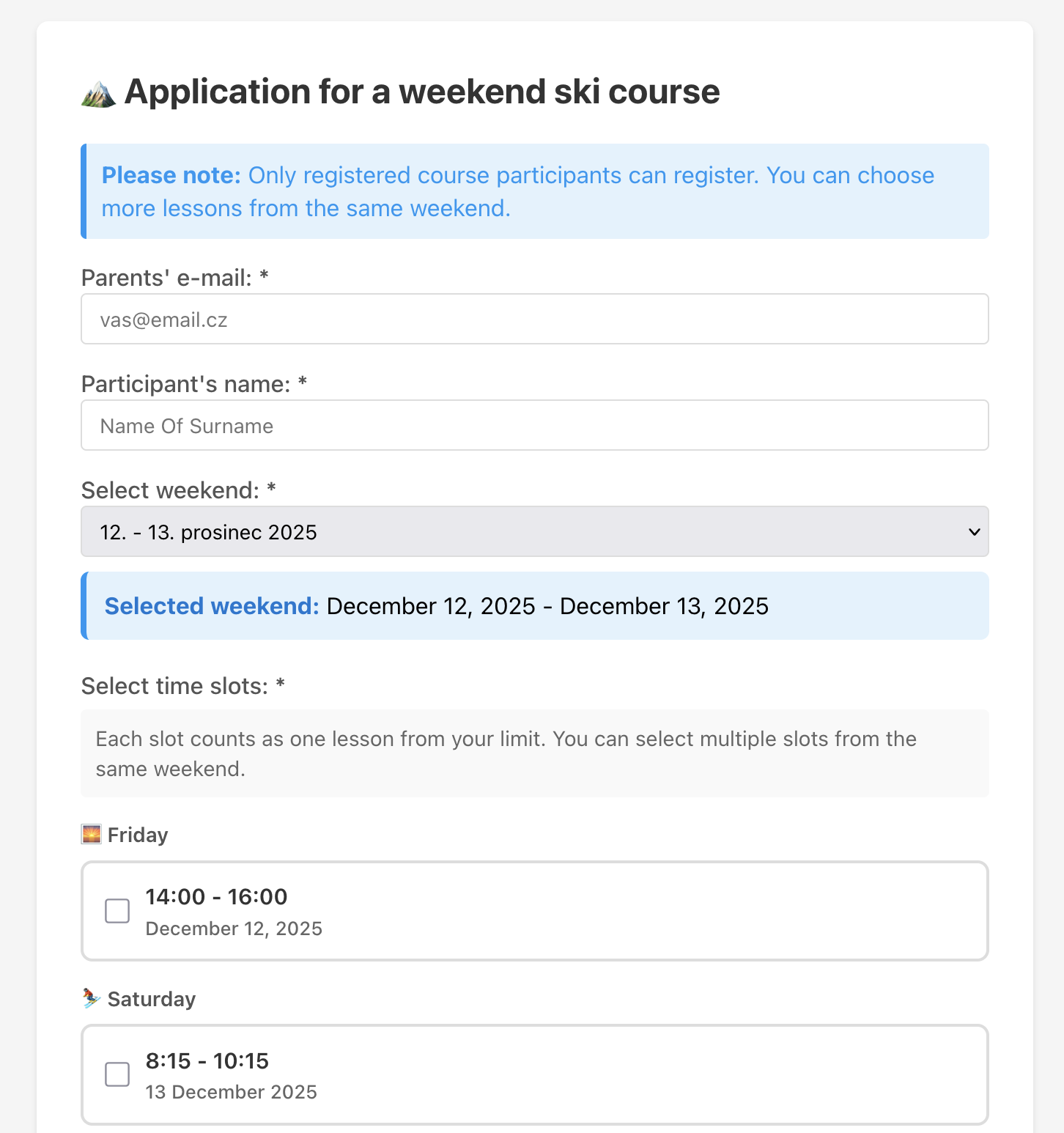 </p><hr /><h2 id="core-problem--solution">Core Problem & Solution</h2><h3 id="problem">Problem</h3><p>Customers purchase a season course, which entitles them to up to 8 lessons out of 12 available weeks during the winter with a possibility a book a given weekend lesson till each wednesday night. Managing these constraints manually, ensuring no over-booking, handling multiple time slots, and enforcing weekly cutoffs, was time-consuming and error-prone.</p><h3 id="solution">Solution</h3><p>A Flask + PostgreSQL web app that:</p><ul><li>Automates registration limits (8 out of 12 weeks)</li><li>Allows two/even three time slots per weekend (Friday/Saturday)</li><li>Automatically closes registration every Wednesday at 24:00</li><li>Provides an admin dashboard with Google Sheets synchronization</li></ul><hr /><h2 id="architecture-overview">Architecture Overview</h2><h3 id="tech-stack">Tech Stack</h3><ul><li>Backend: Flask (Python)</li><li>Database: PostgreSQL (hosted on Railway)</li><li>ORM: SQLAlchemy</li><li>Hosting: Railway.app</li><li>Integrations: Google Sheets API for attendance tracking</li><li>Import: Secure CSV import of registered students from e-shop exports</li></ul><h3 id="key-features">Key Features</h3><ul><li>Unique constraints prevent duplicate registrations</li><li>Schema migration scripts for evolving database models</li><li>Secure environment handling via
</p><hr /><h2 id="core-problem--solution">Core Problem & Solution</h2><h3 id="problem">Problem</h3><p>Customers purchase a season course, which entitles them to up to 8 lessons out of 12 available weeks during the winter with a possibility a book a given weekend lesson till each wednesday night. Managing these constraints manually, ensuring no over-booking, handling multiple time slots, and enforcing weekly cutoffs, was time-consuming and error-prone.</p><h3 id="solution">Solution</h3><p>A Flask + PostgreSQL web app that:</p><ul><li>Automates registration limits (8 out of 12 weeks)</li><li>Allows two/even three time slots per weekend (Friday/Saturday)</li><li>Automatically closes registration every Wednesday at 24:00</li><li>Provides an admin dashboard with Google Sheets synchronization</li></ul><hr /><h2 id="architecture-overview">Architecture Overview</h2><h3 id="tech-stack">Tech Stack</h3><ul><li>Backend: Flask (Python)</li><li>Database: PostgreSQL (hosted on Railway)</li><li>ORM: SQLAlchemy</li><li>Hosting: Railway.app</li><li>Integrations: Google Sheets API for attendance tracking</li><li>Import: Secure CSV import of registered students from e-shop exports</li></ul><h3 id="key-features">Key Features</h3><ul><li>Unique constraints prevent duplicate registrations</li><li>Schema migration scripts for evolving database models</li><li>Secure environment handling via config.py</li><li>Optimized admin interface for real-time oversight</li></ul><hr /><h2 id="live-deployment">Live Deployment</h2><p>🌐 Live web app: https://vikendovelyzovani.zadov.cz/
(Used in production by Ski Zadov to manage weekly registrations for the ski school.)</p></section><footer class="page__meta"></footer><nav class="pagination"> Previous Next </nav></div></article></div></div><div class="page__footer"><footer> <footer class="page__footer"><div class="page__footer-follow"><ul class="social-icons"><li> GitHub</li></ul></div></footer></footer></div></body></html>url: /portfolio/registration-system/ link: teaser: /images/registration_system.png